Improving the algorithm?
I wonder if the algorithm should be changed in order to add this observation to the "Pre-Maverick" project:
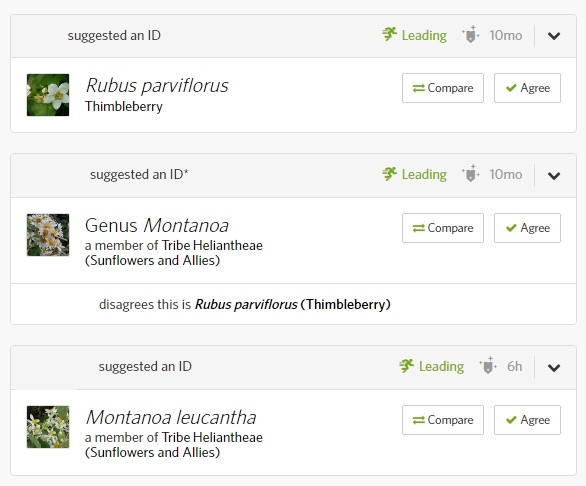
This observation has Community ID (CID) = Dicots.
If an ID Family Asteraceae is added, then the CID becomes Family Asteraceae and the 1st ID becomes Maverick.
If an ID Montanoa leucantha is added then the CID becomes Genus Montanoa and the 1st ID becomes Maverick.
So, it's truly a Pre-Maverick (one more ID is enough to make it a Maverick), but the CID cannot be fixed at rank species with only one more ID.
Shall similar observations be added to the Pre-Maverick project?




Comments
Open question about the Pre-Maverick project.
@annkatrinrose @catchang @dianastuder @lappelbaum @lincolndurey @pisum @tonyrebelo
I am torn between we had retrieved over half a million 'obs with probs' so perhaps we shouldn't change the rules.
And we could spread the net a little wider.
It has dipped as the archive climbs to meet it.
Pre-Maverick 470 K
Pre-Maverick Archive 47 K
That would work OK for me.
I am only really interested in southern Africa so we have
PreMav: 9,900 (say 10k) https://www.inaturalist.org/observations?captive=any&place_id=113055&project_id=156949&subview=map&verifiable=any
PreMavArc: 3,300 - so we have resolved 30% of our PreMavs.
For fun: only 34 Proteaceae in PreMav for s Africa and 94 globally: https://www.inaturalist.org/observations?captive=any&place_id=113055&project_id=156949&subview=map&taxon_id=64517&verifiable=any
Will try and sort these out.
That's exactly the kind of observations with disagreements that I'm looking for so I would appreciate having them included to more easily find them. When I work with the pre-mavericks, I will often limit to those stuck at Life or plants at higher levels from kingdom down to family to see if I can slot them into a genus or at least tip the balance in the right direction. Some of them won't be identifiable to species (e.g. a lot of mosses that require microscopy etc) so family or genus may be where they'll end up but that's still better than Plantae.
It could be another "Pre-Maverick 2" project, containing only these other observations.
And we keep the "Pre-Maverick" project unchanged.
I'd definitely be interested in pre-maverick 2.
I don’t have an opinion as I personally don’t track numbers, etc. The original project is helpful but I do notice
a higher ratio of cultivated records which could use data quality tags.
Yes please - as Pre-Maverick 2. With a fresh target.
I am less interested in tracking the numbers, that in keeping the different sets of problems apart.
i'm not entirely convinced that projects + bots are the most efficient way to handle the problem. fundamentally, the thing that i think a lot of identifiers are looking for here are disagreements (including "pre-mavericks"), and there's just not a good way to filter for disagreements right now.
in my head, the best path forward is first to figure out what kinds of disagreements people are generally interested in. my intuition is that (1) observations with multiple leading IDs (or multiple descendant taxa compared to the observation ID), (2) observations with a maverick as the latest ID, and (3) observations with ancestor disagreements are the 3 main categories of observations of interest that are hard to search for currently, but i suspect there are more categories of interest.
i'm thinking that the most efficient solution may be to have a web page that allows folks to filter on demand by the standard iNat parameters and then search within, say, up to the first 10000 results of that first pass for records that fit the disagreement cases. the final result would be something like sets of up to 200 comma-separated IDs for these disagreement cases, along with various links that could take you to the Explore or Identify pages for any of the selected sets of IDs (or just copy the list of IDs to your clipboard for other uses). this kind of approach may not be as user-friendly as a project, but it allows you to potentially handle many more variants of cases in an efficient way than i think the projects approach can handle, and it would handle things in a more real-time manner (whereas the projects approach would be only as up-to-date as the bot adds and removes observations from the project).
alternatively, maybe that second pass filter for disagreement cases could be handled as a browser extension rather than a separate webpage. @sessilefielder already has an extension that i think many hardcore identifiers use. so i wonder i the kind of thing that i'm describing would make most sense to be incorporated into something like that extension?
It's not easier for iNat to provide such feature(s), because of performance issues and optimizations that would (most likely) require changes in the database. I am still waiting for an iNat feature for filtering observations of users that have opted-out (of community taxon) (envisaged in March 2023), so don't expect too much too early with regard to pre-mavericks. I can't answer for iNat, of course, and will not discuss this too much. In short, ask iNat for the feature (= more filters in the API), then we will see if the web site provides a user interface or if we need to tweak the URLs or to use a browser extension.
Projects + bots is a technical solution to the performance issue, because the bot is run once and then every one has access to the results, stored in the projects. The drawback is that the results are not uptodate, but the "Pre-Maverick Archive" project will reduce this drawback.
just for clarity, the web page that i'm talking about in the 3rd paragraph in my previous comment would not be provided by iNat. it would be a separate web page just for helping to filter for disagreements outside of the standard iNat filtering.
ultimately, i think the ideal final solution in iNat itself would be to modify the existing
identificationsAPI parameter to handle useful scenarios that are of interest (to be defined via further discussion), rather than the not-very-functional some_agree, most_agree, etc. scenarios.I agree.
The project is easy to use (filter by project).
And visible, generating questions - what's a Pre-Maverick?
And mostly drawing support = 138 members.
API and filters is reaching a different (and smaller?) group of people. Not for me.
for what it's worth, some kind of second-pass filtering mechanism -- whether implemented in a separate web page or in a browser extension that modifies the Explore / Identify pages -- could also facilitate more complex queries, like queries that use OR conditions, etc. i just wanted to mention that in case sessilefielder looks at this and does a preliminary pro / con analysis.
i made something that may help to automate the process of filtering for observations with disagreements: https://forum.inaturalist.org/t/provide-a-way-to-filter-observations-by-disputed-ids/6698/15. this approach is a simpler approach than what i described previously. it also has its limitations, but it should be relatively adaptable and should be able to get data in close to real time.
Thanks a lot!
Add a Comment