A New Vision Model!
These are dark days, but here's a small piece of good news: we recently released a new version of the computer vision model that iNaturalist uses to make automated identification suggestions. It takes several months to create a new model, and we released this one on March 3, 2020.
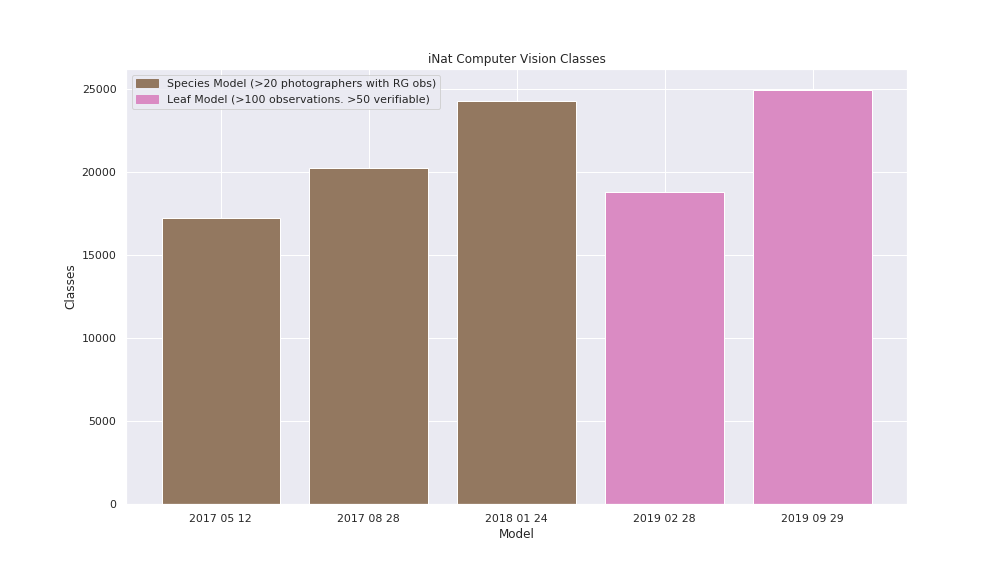
We want to take this opportunity to share how the model, its input data, and our process has changed over time. The first thing to understand is that the model isn’t updating on a day-to-day basis. Each time we train a new model, we use a snapshot of the images on iNaturalist associated with observations that have complete data (i.e. they have coordinates, a date, and media) without any problematic flags (e.g. if the location is marked incorrect, we exclude it) and a taxon. This means that we do include images from observations of captive and cultivated organisms. Lastly, in recent models, a taxon must have at least 100 verifiable observations and at least 50 with a community ID to be included in training (actually, that’s really verifiable + would-be-verifiable-if-not-captive, because we want to train on images of captive/cultivated records too). That’s quite different from the criteria for our first three training sets, which were filtered by the number of photographers. Here’s a chart showing the change in taxa included in the model over time. Brown bars show models that include taxa (“classes” in the chart) by number of photographers, pink by number of observations.
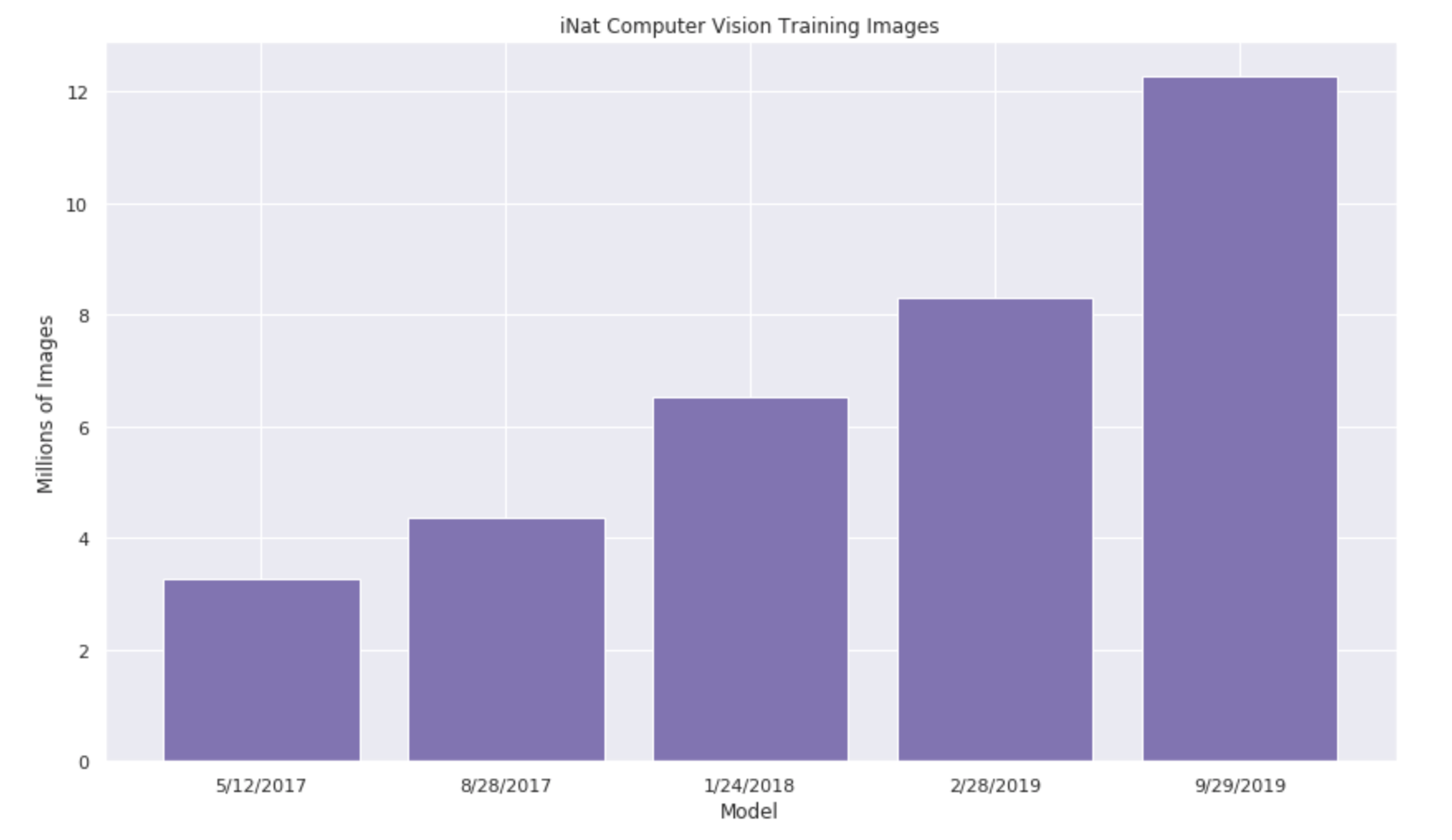
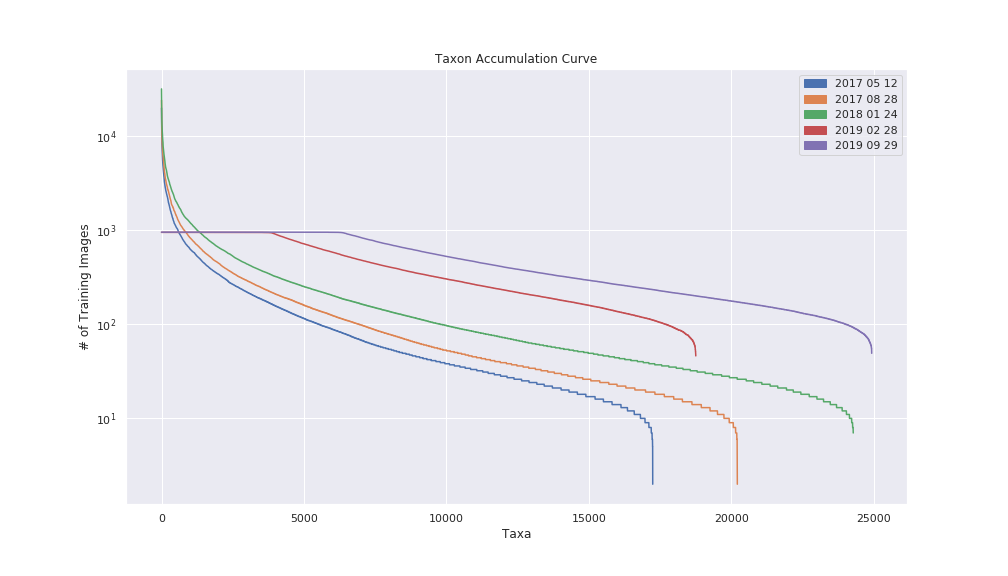
As iNaturalist grows, the pool of images for training grows too. You can see the growth over time in this graph, which shows the date that the training began. For this most recent model, it used images from observations meeting the criteria above on September 29, 2019.
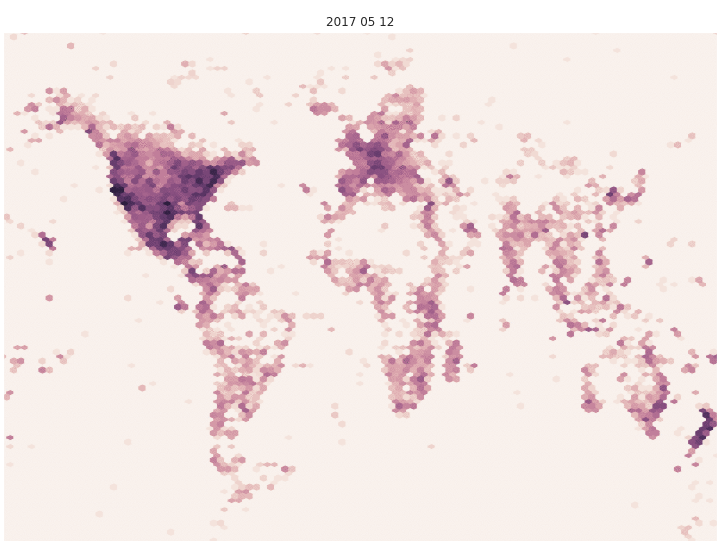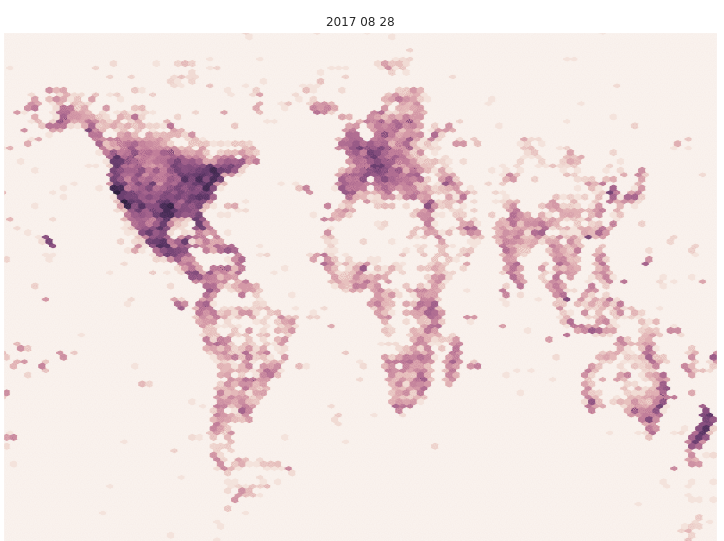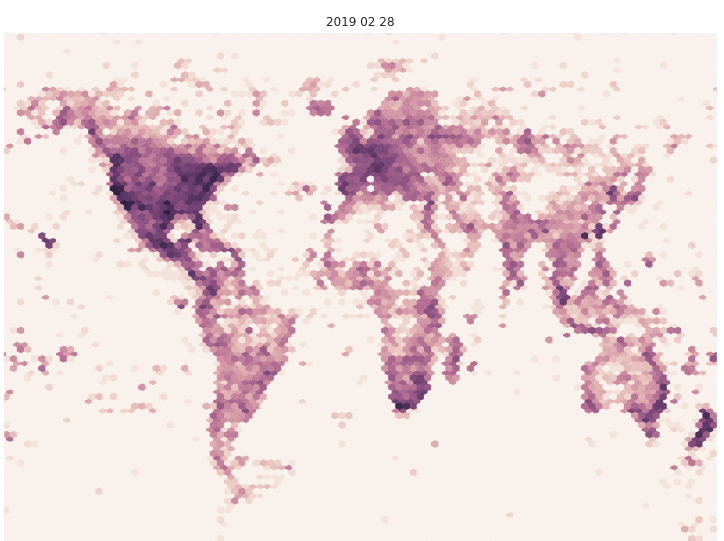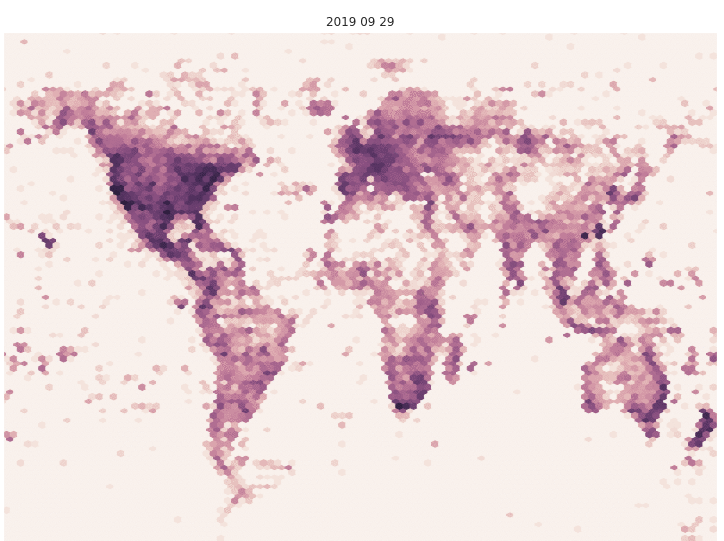
Not only has the number of images grown, but the geographic spread has grown as well. In the figure below, we’ve plotted the locations of all the observations represented in recent models to show the difference in geographic coverage. Value indicates log-normalized number of images per area. Note the increased density in Russia and in the western Pacific Ocean in the September data.
The approach to the data we train with also evolved. For the first three models, we only trained them to recognize species. For the last two models, we’ve been able to train with coarser taxonomic ranks. For example, if each species in a genus has 10 photos, that might not be enough data to justify training the model to recognize any of those species, but if there are 10 species in the genus, that’s 100 photos, so we can now train the model to recognize the genus, even if it can’t recognize individual species in that genus. This approach allows the model to make more accurate suggestions for photos of organisms that are difficult (or impossible) to identify to species but are easy to identify to a higher rank, e.g. the millipede genus Tylobolus in the western US. In the first 3 models, it would over-suggest the most visually similar species, even if it had no nearby records, e.g. Narceus americanus, a species from the eastern US that looks almost identical to western species of Tylobolus but that doesn’t occur in the same areas. In the diagrams we’re sharing here, we refer to this as the “leaf model” because it adds more “leaves” to the taxonomic tree that the model recognizes.
The graph below shows the increase in the number of taxa included in the model that began training in February 2019 compared to the newly-released model that was started training in September 2019. Starting with the Feb 2019 model, we now cap the number of photos we use for each taxon at 1,000 to prevent over-training, hence the flat tops of those two curves.
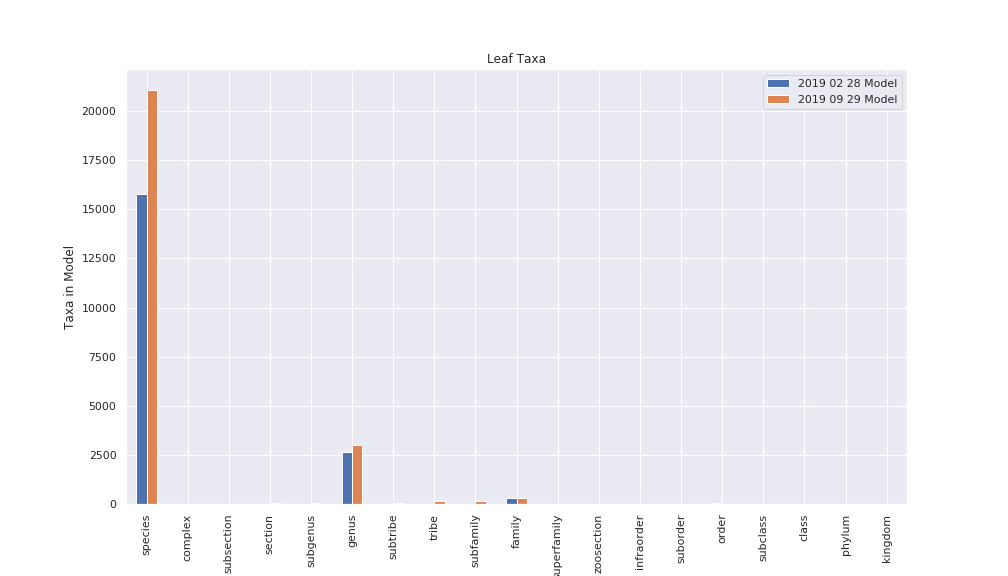
To see how the number of taxa included at different ranks compares between the February 2019 and September 2019 training sets, compare the bars below. We added non-Linnean ranks like tribe and superfamily in the September training, so there’s no expected growth for those, but note the drastic increase in species.
As the amount of data increases, so do the resources required for training. We trained most of our models on a machine in our office at the California Academy of Sciences using graphics cards donated by Nvidia, but for the February 2019 training we experimented with rented hardware at Microsoft Azure using funds donated by Microsoft. Although we were able to spend fewer days training at Azure, it was too expensive for us to afford indefinitely, so we’ve returned to training on our in-house hardware, allowing Alex to more completely geek out on our custom rig. Here’s a chart showing how long its taken to train each model:

We are grateful to everyone in the iNaturalist community who shares and/or identifies observations that make this possible. We hope that the models become increasingly useful to more and more members of the community. With over a million species in the world and 250K on iNaturalist so far, we have a long way to go. We appreciate the many hours of research insights from Grant Van Horn, and we are grateful for the open source software developed by Grant & Visipedia that powers the training of these models. We’d also like to thank Nvidia and Microsoft for supporting our efforts to provide free automated species suggestions to the world.
Written by Carrie, Ken-ichi, & Alex




Comments
I am always impressed how good the suggestions are. Good to know more background info on how this is achieved!
Super!!
Do you guys have a strategy in mind for the rarer species, other than to wait until they get 100 photos?
The common species feature in field guides and many references. But it is the rarer species that make iNaturalist unique. But a high proportion of the really rare species will never get to 100 observations in the next few decades. At present we are getting to 10% of species on iNat suitable for the AI, with a lot less in more biodiverse areas.
Is there any technology available or in the pipeline that might allow us to approach 50% or 75% of species on iNaturalist on the AI?
Would we be able to afford it?
For conservation, for research, for attention - it is the rarest species that we need to focus on the most ...
The ultimate is when AI could tell us "this is a new species ..."
Thanks for this journal update, Ken-ichi. Sharing with some folks too.
Amazing!
Hi all,
The current model is really amazing! Here in Russia, we spotted some time ago that merely all European plant species are recognized automatically with almost no mistakes. That was obvious and so incredible, that I've made a post about this in our project's journal (https://www.inaturalist.org/projects/flora-of-russia/journal/31726-) three days ago. As for plants, the model became more efficient in sedges and grasses. Thus, some common species are now recognized a bit worse due to the inclusion of similar rarer species.
We are always encouraging our observers to make and upload more pictures from various sides within one observation to accumulate 100 pics faster. Hope, this works.
Works really great in well-sampled Central Europe and for the more frequent species in Africa it is improving! Would it be possible to include the known distributions and seasonality into the suggestions?
Thanks a lot for this update!!
I am surprised that with only (and still only) 20.000 species of the millions on this earth such a good result is possible in Europe with Computer Vision
Statistics
I agree It would be very nice if some directives of known distributions/observations/abundance and seasonality could be added. I thought this would be more easy than making a new model. Results based on statistics instead of CI/AI can be rather good.
Further i am surprised that in the past in earlier models only 20 images in stead of 1000 images already gave a good result. Is the result that much better with 1000 images?
In the past only the first image was used(not for training) for proposing. Is it still important that the first image is the best one ? Or can the model use more photos (detail, habitus).
https://www.inaturalist.org/pages/help#cv-taxa
FWIW, there's also discussion and some additional charts at
https://forum.inaturalist.org/t/psst-new-vision-model-released/10854/11
https://www.inaturalist.org/pages/identification_quality_experiment
https://www.inaturalist.org/journal/loarie/10016-identification-quality-experiment-update
https://www.inaturalist.org/journal/loarie/9260-identification-quality-experiment-update
about a rare species, but the system might still recommend one based on nearby observation
https://forum.inaturalist.org/t/identification-quality-on-inaturalist/7507
https://github.com/kueda/inaturalist-identification-quality-experiment/blob/master/identification-quality-experiment.ipynb
"nearby" means near in space and time
b/c because
Impressive. Glad to know I'm providing some "training"!
So, to get into suggestion pool, species should have at least 100 photographs in observations with RG status? Number of observations does not matter?
Does it mean, that uploading many images of a single observation is good for the vision model? Or only the first image from a single observation is used?
Interesting to see how number of observation in spesies/genus pool correlate with quality of sugestions...It should be interesting curve!)
Congrats on a job well done! I'd wondered why some of my newer observations (just-sprouting plants to boot) had more refined suggestions than usual that turned out to be right when people ID'ed them. :)
Thanks for this awesome update that even I could understand! In an increasingly bleak time iNat continues to be such a beacon of hope and progress and community for me. I'm excited to put the computer vision to work! Thanks :)
Happy news, thanks all round.
@tonyrebelo, regarding rare species, yes, they are important, but are they important for the computer vision system to recognize? I think that's debatable. On the one hand, of course, we want to know when a rare species has been observed even if the observer and the group of people who have seen the observation cannot identify it, both b/c it's useful data and so we can obscure the coordinates. On the other hand, rare species are rare, and thus, people rarely encounter them, so focusing on them too much might only provide a benefit in a vanishingly small sliver of situations, and might even provide a disservice if the system is over-trained on them and leads to a lot of false positive errors (which it already does too much). I think our current system is a good compromise. I should also mention that the vision model and the suggestions system are not the same. The model might not know about a rare species, but the system might still recommend one based on nearby observations. For a very rough description of this process, see https://forum.inaturalist.org/t/identification-quality-on-inaturalist/7507
@apseregin, encouraging people to get pictures from multiple angles is good for human identifiers, and what is good for human identifiers is (usually) good for machine identifiers. In my opinion, you should always think about the needs of people first, not machines. That said, I don't think any human identifier really needs more than 5-6 photo per observation to make an identification, and looking at the observations with the most photos... I think we need to impose some limits.
@marcoschmidtffm & @ahospers, regarding including distribution and seasonality information with our suggestions, we already do. For one thing, nearby injection takes seasonality and geography of the observation being identified and into account ("nearby" means near in space and time). For another, the Compare tool on the web includes geographic info (though not seasonality), and the taxon detail view in the Android app has both seasonality and geography. I'm pretty sure the iPhone app has geography, but maybe not seasonality.
@ahospers, early models had a criterion of 20 photographers, not 20 images. So if we had 20 photos all taken by me, we would not include that taxon, b/c there was only 1 photographer. The assumption behind this was to not over-train on the kinds of images generated by a single person due to equipment used, stylistic preference, etc., but I think the fact that we removed that criterion in later training sets suggests it was not actually useful. It is also not true that we ever only used the first image for vision training.
@krokozavr, I wrote, "in recent models, a taxon must have at least 100 verifiable observations and at least 50 with a community ID to be included." So we are currently using criteria based on number of observations, not number of photos.
FWIW, there's also discussion and some additional charts at https://forum.inaturalist.org/t/psst-new-vision-model-released/10854/11
Thanks. Yes I agree: 95% of users of iNaturalist will post really common species, and for those users the computer vision is just mindblowingly fast and accurate. But at the same time hundreds of iNaturalists could also identify those species, although without any doubt the computer vision will do in a far shorter time, and remove the drudge.
So yes: 95% of your users will be happy. And if that is your goal, or your goal is to identify 90% of the observations on iNaturalist then the computer vision must be very close as good as at ever needs to be.
But the real challenge: the one that we really desperately need help with, are those species for which only one or two people on earth can make the identifications. But even those experts so seldom encounter them that although one has a hunch, one forgets and has to go through the whole rigmarole of keys and diagnoses and checking specimens each time. Surely it is here that computers - that never forget, and always have details to hand (sounds like an elephant) - can be the most use. I am not a purist: I dont care if the computer cheats and uses geography, distribution ranges and flowering time to arrive at a suggestion. And while I realize that we are a niche market and insignificant in the grand scheme of things that caters for the masses, it will really make a difference all round if really rare species that one is not expecting are flagged, or new records of aliens give warnings and if rare and first occurrences on iNat at acknowledged. Todays dreams are tomorrows realities: I hope ...
The first graph here (brown/pink) and the FAQ do say 100 photos/images not 100 obs:
https://www.inaturalist.org/pages/help#cv-taxa
Thanks Cassi, I updated the FAQ and the figure here in this post.
Well done! Thank you for this big step forward.
It was stated that the suggestions do factor in seasonality and distribution, but does the ML model itself incorporate non-image data or is this a purely vision-based model?
No, the vision model does not itself incorporate non-image data other than taxon IDs.
If i add 10 photos to an observation only the first observation is used...not the best or all ten photos. Has this changed ((It is also not true that we ever only used the first image for vision training.)).
But is it that hard to put statistics/distribution in the suggestions? As i have limited time during upload i will not use the tabs about distribution and prefer to have this statics visible/processed in the proposal of the species.
In 2017 the amount of recognised species was 20.000 and now it is still.....20.000?
https://www.inaturalist.org/pages/help#cv-taxa
FWIW, there's also discussion and some additional charts at https://forum.inaturalist.org/t/psst-new-vision-model-released/10854/11
https://forum.inaturalist.org/t/identification-quality-on-inaturalist/7507
This is a good question, I was also interested whether all photos in observation are considered by AI or only the first photo.
Thanks for this information! To me this emphasizes how simple editing of photos before submission (especially cropping) is important. The iNat app for iPhone doesn't have this built in (I don't know about the android one), but the camera/photos app does, so another reason to take the photos outside the iNat app and process them first before submitting to an observation.
On the iPhone you can "unsqueeze" (spread fingers outwards) to zoom in - is that not effectively the same as cropping? It works OK on my iPhone, and on everyone that I have demonstrated that to so far.
Beware of taking pictures outside the app as the locality is usually incorrect when you add them: it defaults to your current position instead of where the photos were taken.
@tonyrebelo I actually did not know that about zooming inside the iNat camera ! Duh. But as to locality, I seldom have any issues with locality on photos taken outside the app. They are usually spot-on.
As a nice activity for home working lunchtimes, I was thinking of taking some photos in our nearby botanical gardens of plants with a secondary photo including their name tags, which I thought might help others as a clear record for id. Marked as cultivated of course. Does the computer vision mind that there's a name tag included in the set of photos?
LOL! you will train the computer vision to read!
I think I was misunderstanding some of the comments about using one photo, so to clarify, we do not use one photo per observation for training the model, but we do use one photo per observation when generating suggestions for a single observation. These are two different processes. The current models we're using are really only designed to take one photo as input. There are other kinds of models, and we could try things like concatenating all the photos in an obs and evaluating that, but we have yet to experiment much with either approach. Personally I'd prefer it if you could choose which photo you get suggestions for (you can kind of do this by changing the order of the photos in the observation).
@lera If you are specifically trying to help train the vision model, then evidence of the organism is the best training material - photos of the organism, or tracks, or scat.
However, as we all know, iNaturalist is much more than a community training a vision model. Please don't change your behavior based on what the model might learn.
@kueda congratulations on the new release.
Regarding this:
I suspect the display of predictions of taxa that are not within the range of an observation account for a very large number of errors. Even if the model doesn't take into account non-visual feature, I imagine you could filter out predictions of taxa that are not found locally and maybe allow advanced users to opt into this feature from their settings. Is there a reason why this has not been done? Is it worth running an A/B test? It should be relatively straightforward to see how many IDs based on model outputs with a high rank in the list returned to the user result in subsequent corrections by the community.
I am excited to see improved AI for observation identification in iNat – it makes me look like I know more than I do. I am assuming this same tool is available both on browser and smartphone? I have had a couple of times recently when iNat has made some poor guesses from my iPhone App. Obviously, you could say my photos aren’t very good, but I’ve been taking bad photos for awhile and iNat has done better in the past. Here are a couple of examples:
The suggestions for this great-tailed grackle were all in the category of pheasants, Grouse and Allies (Family Phasianidae)
https://www.inaturalist.org/observations/40382558
And this western honey bee was thought to be a Hover Fly (Family Syrphidae)
https://www.inaturalist.org/observations/40398561
Don't know if this is helpful or not. Perhaps there's another way to indicate a "poor guess" from iNat.
But do Hoverflies not mimic bees?: so is this a good example to illustrate a poor guess? - presumably the flies fool enough predators to continue with the bee mimicry. If it can fool predators, surely fooling the AI is not a big deal?
@apcorboy this model is being used for the iNaturalist website and iNaturalist Android and iOS apps. It hasn't been released in Seek yet.
For what it's worth, I cropped your honey bee photo and the computer vision model's top suggestion was correct. Cropping can definitely improve results.
Thanks @tiwane, @tonyrebelo for quick, thoughtful responses. I may have been doing less cropping lately. I'll begin cropping again. I cropped the grackle photo and inat made better guesses. I adjusted the exposure and shadows and got even better guesses, though neither suggested grackle as first on list. I think it's just not a very good photo in the end.
Is it be possible to download the model somewhere, to use as a standalone product?
@jtklein, no it's not, though we are considering ways to make it available as an API. You could also experiment with training your own with https://www.kaggle.com/c/inaturalist-challenge-at-fgvc-2017
It seems de model gives better results in Sri Lanka (n=3) ,
If you are looking to a potentially lower-cost but faster training environment or expertise in AI consulting, the University of Illinois, National Center for Supercomputing (NCSA) opened up a Center for AI Innovation. I have no idea what their fee structure is.
http://www.ncsa.illinois.edu/news/story/ncsa_launches_center_for_artificial_intelligence_innovation
They have a cluster with 64 Nvidia GPUs (appropiatately called HAL) that has a job scheduler to share the whole environment. It can schedule up to 64 GPUs to work on one job to speed up training nearly linearly with the number of GPUs.
A suggestion for improving accuracy: When a taxa has more than 1000 photos, prioritize training with the photos from observations that have the highest number of identifications. For instance an observation with three identifications will probably be more reliable than an observation with two identifications. Presuming the identifications aren’t conflicting.
Also, could digitized herbaria samples be used as high reliability training data? It could help with rarer species or easily confused species.
@markg729 - as a human identifier there are entire genera in the Proteaceae (e.g. Leucadendron) where the characters for identifying fresh material are entirely separate for those identifying herbarium material. They are chalk and cheese: the diagnostics for field ID (orientation, colour, shape) are squashed to oblivion in herbarium specimens, or are not captured at all (branching pattern, growth habit, plant size), and one has to resort to microscopic features rather than obvious morphological features easily seen on photographs.
Also the training seems to rely quite a lot on background - for instance a photo of rocks will suggest Dassie and Klipspringer in southern Africa, which wont be present in herbarium specimens.
A good idea, but will it work, or just confuse the process.
Is it wise to train the the CVM in a global mode. Might it not be simpler, faster, more efficient to do the training on a continent by continent basis.
Alternatively, have a two tiered model system: 1. ID to iconic group, 2. ID within iconic groups (?by continent for groups with over X000 taxa).
I dont know the logistics of training 1 model of 100,000 taxa versus 10 models of 10,000 taxa - just a suggestion if it is feasible.
But it would help solve many of the bad misidentifications we are seeing (esp. in invertebrates) were the majority of species used in training are from the USA, and the CVM is identifying southern African species (too few observations for training) to these, and naive users are posting these wrong IDs.
Is this model still only trained on RG observations? Thanks!
@edanko, no, and I don't think it ever was in a strict senese. RG conflates too many aspects of "quality" to be useful for this purpose on its own. For example, we really need the model to be able to recognize humans, but observations of that species are "Casual" by default. Training is also a bit too complicated for us to make simple statements like "we train on these photos and not these other photos." I'll attempt a less-simple explanation of how we're doing it for our current models (has changed in the past, might change again in the future).
Training data gets divided into three sets:
Training: these are the labeled (i.e. identified) photos the model trains on, and include photos from observations that
have an observation taxon or a community taxon
are not flagged
pass all quality metrics except wild / naturalized (i.e. we include photos from captive obs; note that "quality metrics" are the things you can vote on in the DQA, not aspects of the quality grade like whether or not there's a date or whether the obs is of a human))
Validation: these photos are used to evaluate the model while it is being trained. These have the same requirements as the Training set except they represent only about 5% of the total
Test: these photos are used to evaluate the model after training, and only include observations with a Community Taxon, i.e. observations that have a higher chance of being accurate b/c more than one person has added an identification based on media evidence
You'll note that we're potentially training on dubiously-identified stuff, but we are testing the results against less-dubious stuff (you can see what these results look like in the "Model Accuracy" section of https://forum.inaturalist.org/t/identification-quality-on-inaturalist/7507). The results are, strangely, not so bad. Ways we might train on less-dubious stuff (say, CID'd obs only, ignore all vision-based IDs, ignore IDs by new users, ignore IDs by users with X maverick IDs) all come with tradeoffs and all, ultimately, limit the amount of training data, which I'm guessing would be a bad thing at this point for the bulk of taxa for which we have limited photos. We might experiment with these ideas in the future, but right now it's about all we can manage to keep cranking out a model or two a year.
I can get computer-generated suggestions on the phone app, but I can't figure out how to get them from the website. Thanks.
click in the "Suggest an Identification" box and wait a second or two ...
If cost of resources for AI training is an issue, have you looked at resources like XSEDE? Some supercomputer centers have clusters of systems set up to do AI training. XSEDE is no cost to use if they approve your usage. https://www.xsede.org/for-users/getting-started Some of the organizations in XSEDE have their own collaborations going with other universities and industry, such as NCSA's Center for AI Innovation where they provide facilities and expertise in scalability and modeling (these usually have a fee but might be less than a for-profit organization like Amazon).
Does anyone know how frequently the computer vision retrains? I have tried searching the forum but couldn't find the answer there, so apologies if it's already been answered. For example, I have been identifying Apina callisto (https://www.inaturalist.org/taxa/244471-Apina-callisto) (mainly the caterpillars) since early August, but it is not appearing as a CV suggestion yet. It is a very common species in south-eastern Australia and appears in large numbers some years, but is not super well known by the public.
The training is about once a year: from the graph above training dates are nominally :
May 2017
Aug 2017
Jan 2018
Feb 2019
Sep 2019
Mar 2020
Yes it is not ongoing, and training for a particular taxon only starts with 50 research grade observations. But from the graph on https://www.inaturalist.org/taxa/244471-Apina-callisto of the "history" this should probably have made the cut for the March 2020 training, although if most were unidentified and were only identified in August, then they would have missed the last cut, and will only be trained in the next batch. But if the next batch will be in Sept 2020 or March 2021 I do not know.
Ah thanks @tonyrebelo , I feel silly for missing that detail on the graph. No worries, I am guessing it will be trained and ready to identify these caterpillars next southern hemisphere late winter when they're out again! And maybe even in time to identify the adults which emerge in autumn (April-May 2021) ?
I wonder for some groups if the training for the adults should be done separately from the juveniles. Would say 30 pillars and 20 adults be enough to train the AI for a species? Of course, the majority of observations are probably not annotated for this.
For instance, in your species https://www.inaturalist.org/taxa/244471-Apina-callisto - see the Life Stage tab: you have
25 adults
70 juveniles
& 55 not annotated as to adult or juvenile.
I'm not sure whether the computer vision takes the annotations into account (yet)? But sounds like something worth doing regardless, I can definitely annotate those 55 :)
Just to clarify, it's not exactly 50 RG observations anymore (although it's close):
The CV training doesn't take annotations into account. Definitely something to explore in the future, though.
There are 25.000 species in the model and about 300.000 species observed in iNaturalist..
https://www.inaturalist.org/blog/42626-we-passed-300-000-species-observed-on-inaturalist#comments
Any hints as to when a new model might be released?
Yes, that would be nice. It might allow us to encourage users to try and get some low hanging fruit ready for the inclusion in the model.
So we need 100 observations with pictures of which 50 must be Research Grade (or RG+not wild)?
A deadline would be cool!
We're currently training a new model based on an export in September that had ~18 million images of 35k+ taxa. It's running with the same setup that we've used on previous models, but with a lot more data, so it will probably take ~210 days and be done some time next Spring. We're simultaneously experimenting with an updated system (TensorFlow 2, Xception vs Inception) that seems to be much faster, e.g. it seems like it might do the same job in 40-60 days, so if it seems like the new system performs about the same as the old one in terms of accuracy, inference speed, etc., we might just switch over to that and have a new model deployed in January or February 2021.
FWIW, COVID has kind of put a hitch in our goal of training 2 models a year. We actually ordered some new hardware right before our local shelter in place orders were issued, and we didn't feel the benefit of the new hardware outweighed the COVID risk of spending extended time inside at the office to assemble everything and get it running. Uncertainty about when it would be safe to do so was part of why we didn't start training a new model in the spring (that and the general insanity of the pandemic), but eventually we realized things weren't likely to get much better any time soon so we just started a new training job on the old system.
The Academy is actually open to the public again now, with fairly stringent admission protocols for both the public and staff, so we might decide to go in an build out that new machine, but right now we're still continuing with this training job and experimenting with newer, faster software at home.
@kueda Thank you so much for the update. I had been hoping that we would see a new one any day now based on the previous releases, but I definitely understand. This year has put a hitch in just about everyone's goals. Best to stay safe, and I look forward to seeing a new model sometime next year.
Great update. Keep up the fine work, and stay safe!
@kueda totally understandable! Thanks for all your hard work, but first and fore most stay safe.
Does any body has this article ? Overview of Computer Vision in iNaturalist
Corresponding author: Ken-ichi Ueda (kueda@inaturalist.org)
Received: 29 Sep 2020 | Published: 01 Oct 2020
Citation: Ueda K-i (2020) An Overview of Computer Vision in iNaturalist. Biodiversity Information Science and
Standards 4: e59133. https://doi.org/10.3897/biss.4.59133
--
Abstract
iNaturalist is a social network of people who record and share observations of biodiversity.
For several years, iNaturalist has been employing computer vision models trained on
iNaturalist data to provide automated species identification assistance to iNaturalist
participants. This presentation offers an overview of how we are using this technology, the
data and tools we used to create it, challenges we have faced in its development, and
ways we might apply it in the future.
Presenting author
Ken-ichi Ueda
Presented at
TDWG 2020
@ahospers I think that was a conference presentation, so the article isn't available online.
It's available here: https://www.youtube.com/watch?v=xfbabznYFV0
Wow that is fast. Thank you...
A, you stole my question ;-). Thank you for the answer. Will take a look at YouTube later.
"we do not use one photo per observation for training the model"
Are photos of labels (botanical garden) a "noise" impacting the training?
Could these photos be skipped?
"we do use one photo per observation when generating suggestions for a single observation"
Is it always the 1st photo (= cover)?
Is it affected by reordering photos? (When the current cover is not anymore the 1st photo uploaded).
I usually take a closeup picture of a flower, a closeup picture of a leaf, and a picture of the whole plant. For Subfamily Cichorioideae, I guess the leaf shape and aspect is the most important (provided the Subfamily is identified in the first place), then the whole plant aspect, and only then the flower (~ they all look the same). I guess it would be better not to use the flower closeup for generating suggestions?
A bit of humour.
No, if anything they're helpful for the vision model b/c they provide some training data for species that might be difficult to observe in the field, and help the model recognize morphological differences of plants in cultivation. Of course, to keep me (and maybe others?) from going insane, I'd very much appreciate it if people marked them as captive / cultivated.
Yes.
Yes.
@kueda I think the question is whether photos of signs / plates showing the name of a plants in botanical gardens are impacting the vision model.
Yes.
This Dendrobium does not get any Dendrobium suggestion. Could a manual restriction to Dendrobium help the AI to find the species?
Ah. I don't know, but I doubt it.
is the FAQ/ document with questions mentioned in https://youtu.be/xfbabznYFV0?t=3633 some where availble ?
And i was wondering if the computer which trains the model has only one videokart to check and make the model or if the computer had many videocards in it.
The Model looks great. I am excited to see improved AI for observation identification in iNaturalist. Just curious 1000 images gives the accurate result or 20 images in the last posts?
Add a Comment